요약
- Greedy Algorithm(탐욕 알고리즘)은 최적화 문제를 해결하는 알고리즘이다.
- 최적화 문제는 가능한 해 중에서 가장 좋은 해(최소나 최대값)를 찾는 문제이다.
Greedy Algorithm
탐욕 알고리즘은 주어진 상황에서 최선이라고 판단되는 선택을 하기 때문에 항상 좋은 선택을 고르지는 않는다.
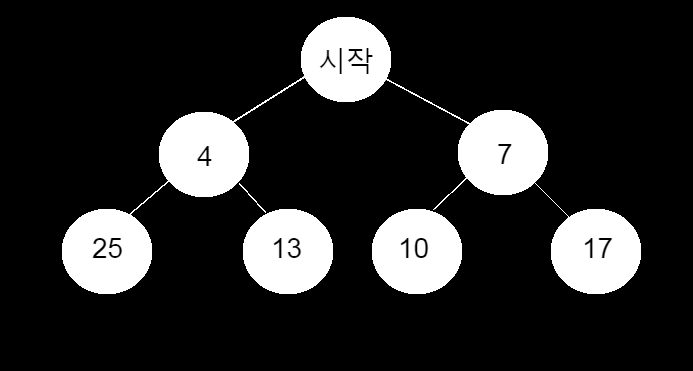
- 위의 트리에서 탐욕알고리즘은 가장 큰 수를 찾을때 왼쪽 자식 노드의 25의 값이 가장 크지만
첫 번째 선택에서 4보다 큰 7을 선택하게 된다. 항상 좋은 결과를 얻을 수는 없다.
1. 동전 거스름돈
- 문제: 물건을 사고 돈을 지불한 후 거스름돈을 받는데, 가장 적은 개수의 동전을 받고 싶다.
- 남은 액수를 초과하지 않고 욕심내서 가장 큰 액수의 동전을 선택하면 된다.
- Pseudo-code
1 | /* 입력: 거스름돈 액수 W */ |
2. 최소 신장 트리
- 최소 신장 트리는 주어진 가중치 그래프에서 사이클이 없이 모든 점들을 연결 시킨 트리들 중 선분들의 가중치 합이 최소인 트리이다. 크루스컬 알고리즘과 프림 알고리즘으로 구현할 수 있다.
- 주어진 그래프의 신장 트리를 찾으려면 사이클이 없도록 연결 시키면 된다.
- 크루스컬 알고리즘으로 구현을 한다면, 가중치가 가장 작은 선분이 사이클을 만들지 않을 때에만 선분을 추가시킨다.
- Pseudo-code
1 | /* |
3. 마시멜로 실험
알고리즘과 심리학 실험??
- 마시멜로 실험은 아이들에게 각각 첫 번째 마시멜로를 주고 “나중에 돌아오면 하나를 더 주겠다” 라고 한 후
반응을 살펴보는 것이 이 실험의 기본적인 실험의 설정이다. 첫 번째 선택에서 마시멜로를 먹어버리는 아이들이
있는데 그 아이들은 가정환경의 영향 때문에 연구원의 말에 의심을 품고 먹어버린다는 것이다. - 그리디 알고리즘으로 생각해 보면, 선택이 주어졌을때 항상 마시멜로의 개수가 많은 선택을 하는 것이다.
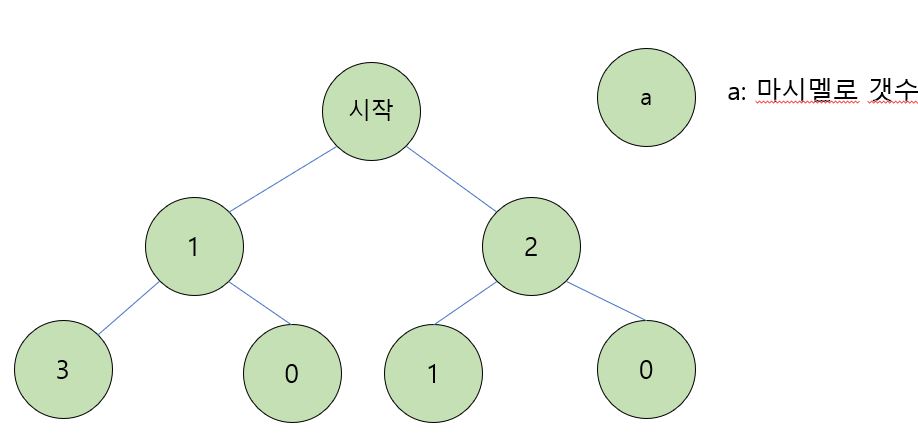
이미지: PPT 캡쳐
- 위의 트리를 보면 첫 선택에서 더 많은 갯수의 마시멜로를 선택을 하면 다음 선택에서는 추가적으로 단 1개의 마시멜로를 가지게 된다. 총 갯수를 생각해 보면 최대 4개를 얻을 수
있지만 그리디 알고리즘에서는 그렇지 못하다.
이 마시멜로 실험은 이후에 문제가 많다고 알려졌지만 그리디 알고리즘의 성격을 가지고 있어서 작성하였다.
정리
그리디 알고리즘 문제는 분할정복 알고리즘보다 구현하기가 수월했던것 같다. 하지만 그만큼 데이터셋이 많아졌을때 효율적이지 않다는 단점도 가지고 있다.
문제가 주어졌을때 효율적으로 해결하기 위해 상황에 맞는 알고리즘을 적용하는 능력이 중요한 것 같다.
그리디 알고리즘의 사용 예시로 AI 결정 트리 학습법을 찾아 보았다. 통계학과 데이터 마이닝, 기계학습에서 사용하는 예측 모델링 방법중 하나라고 한다. 아직 블로그에 작성하기에는 좀더 공부가 필요할 것 같다.
REFERENCEES
- 알기쉬운 알고리즘
- 중앙SUNDAY