유전 알고리즘이란?
유전 알고리즘은 다윈의 ‘적자생존’의 개념을 최적화 문제를 해결하는데 적용한 것이다. 생물체가 적응하면서 진화해가는 것을 모방하여 최적해를 찾는 방법이다.
알고리즘 구성
- 초기 후보해 집합을 생성
- 선택 연산
- 교차 연산
- 돌연변이 연산
사용할 데이터셋
Kaggle에서 Tesla Stock Price 데이터를 사용하였다.
Tesla Stock Price(Kaggle)Open 열과 High열, Low열을 사용하였다. Open 가격에 따른 High와 Low의 평균값을 나타내었다.
유전 알고리즘으로 예측하기
데이터 가져오기
Tesla Stock Price의 csv 파일의 값을 읽어 배열에 저장하는 코드이다.
arr에는 Open 가격을 넣고 arr2와 arr3에 각각 High와 Low값을 가져온 후 평균값을 avg 배열에 저장 하였다.저장한 데이터의 형식은 float형을 사용하였다.
1 | # ----------------주어진 데이터셋-------------------- |
초기 후보해 집합을 생성
- 먼저 초기 후보해 집합을 구한다.
- Open가격 최소와 최대, 평균가격의 최소와 최대를 지정한다.
1 | Openmin = 2 |
- 4개의 값을 받아와 기울기 a의 값 4개를 얻는다.
1 | # 초기 식 y = ax |
1 | # 초기 a 4개 구하기 |
선택 연산
- 각각의 값에 대해 비율을 지정하고 랜덤값과 비교하여 새로운 배열에 넣는다.
1 | # 선택 연산 |
교차 연산
- 교차 연산을 하기 위해 선택연산에서 나온 값들을 이진수로 변경해 준다.
- bin(x) 함수의 값은 “0b0100”이므로 0으로 대체해 준다.
1 | # bin() format |
- 교차 연산은 각 염색채들을 교차하여 새로운 해집단을 생성한다.
1 | # 교차 연산 |
돌연변이 연산
- invert 함수가 돌연변이 연산을 수행한다.
1 | # 돌연변이 한 값 저장하기 |
- 돌연변이 연산은 교차된 염색체들중 랜덤한 확률로 비트가 반전이 된다.
1 | # 돌연변이 연산 |
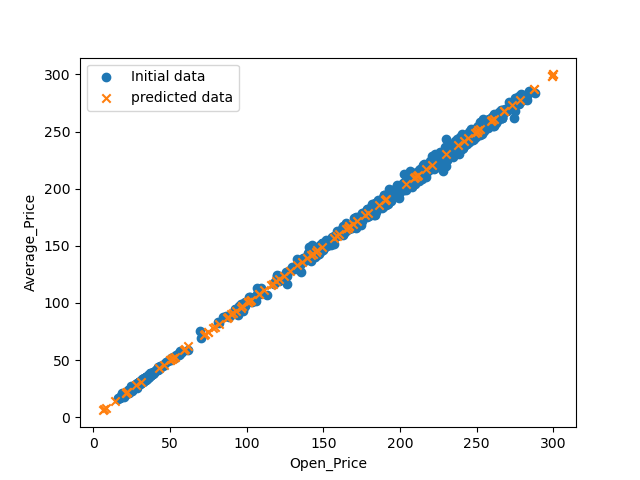
데이터 산점도
- 초기 데이터의 산점도와 예측된 값들의 산점도이다.
- pandas library를 사용하여 초기 데이터와 예측된 데이터를 DataFrame에 넣고, matlibplot library를 이용하여 산점도를 그렸다.
1 | # pandas library로 DataFrame 지정 |
- 초기 데이터는 파란색 o모양 마커를 사용하였고, 예측된 데이터는 주황색 x모양 마커를 사용하였다.
- 최종 예측된 기울기는 1이다.
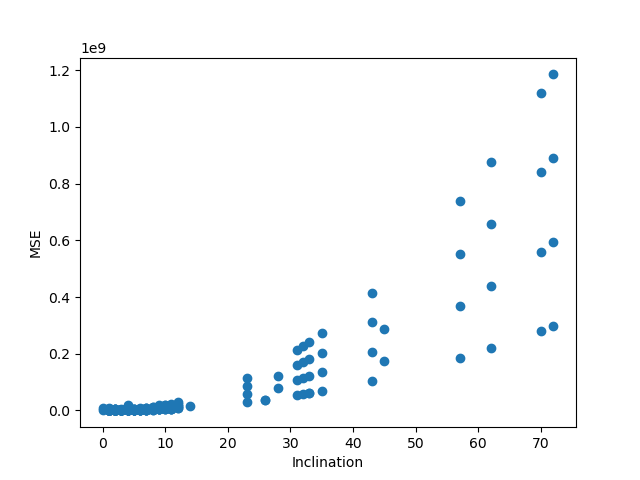
MSE(평균 제곱 오차)
- 머신러닝에서 뿐만 아니라 영상처리에서도 사용되는 추측값에 대한 정확성을 측정하는 방법이다.
- 기본식의 형태는 다음과 같다.
MSE = 1/n ∑ni=1(Y’i - Yi)2 - MSE의 값이 작을수록 원본과의 오차가 적으며 추측한 값의 정확도가 높은 것이다.
- 아래 MSE 그래프를 보면 원래 기울기와의 오차가 클수록 MSE값이 커지는 것을 볼 수 있다.
- 코드가 실행될 때 어떤 값들을 예측하고 지나가는지 알기위해 각 함수 출력도 같이 하였다.
- MSE의 값이 가장 작은 기울기가 1로 나왔다.
출력한 값들이다.
1 |
|
정리
- 유전 알고리즘을 파이썬으로 구현해 보았다. 이차함수나 지수함수가 나오는 데이터를 이용하고 싶었지만, 데이터를 찾는것이 쉽지 않았다.
- 처음에는 구현하기 힘들것이라고 생각했었다. 알고리즘 동작 구성을 이해하고, 차근차근 구현해 보니 잘 짜여졌다.
- 기상청에서 제공하는 서울시의 온도와 습도의 관계 데이터도 사용해 보았지만, Tesla Stock Price 데이터가 좀 더 정확한 것 같아 선택하게 되었다.