강화학습이란?
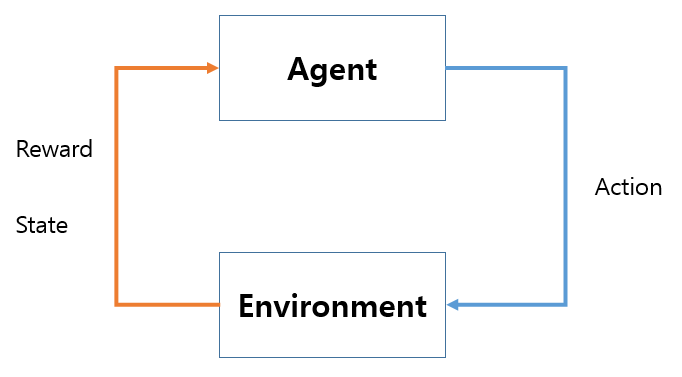
- 에이전트가 환경으로부터 얻는 보상을 통해 좋은 행동을 더 많이 하게 하는 학습 방법이다.
강화학습 기초
Markov Decision Process(MDP)
- 순차척 행동을 결정하는 문제를 풀때 MDP를 사용한다.
상태: 에이전트가 관찰 가능한 상태의 집합
행동: 에이전트가 상태에서 할 수 있는 행동의 집합
보상함수: 환경이 에이전트에게 주는 정보. 에이전트가 학습할 수 있는 정보
상태변환 확률: 에이전트가 어떠한 상태 s에서 행동 a를 해서 다음 상태 s’에 도달할 확률
감가율: 받는 보상정보를 수학적으로 표현하기 위함
Value Function
반환값(return): 에이전트가 탐험하며 얻은 보상
Gt = Rt+1 + 𝛾Rt+2 + 𝛾2Rt+3 …가치함수(value function): 얼마의 보상을 받을지에 대한 기댓값
v(s) = E[Gt|St = s] = E[Rt+1 + 𝛾Rt+2 + 𝛾2Rt+3 + … |St = s]
Policy
- 정책은 모든 상태에서 에이전트가 할 행동이다.
𝜋(𝑎|𝑠) = P[At = a| St = s]
Bellman Expectation Equation
- 벨만 기대방정식은 현재상태의 가치함수와 다음상태의 가치함수 사이의 관계를 말해준다.
v𝜋(s) = E𝜋[Rt+1 + 𝛾𝑣(St+1) | St = s]
Q-Function
- 큐 함수는 어떤 상태에서 어떤 행동이 얼마나 좋은지 알려주는 함수이다.
- 상태와 행동이라는 두가지 변수를 가진다.
q𝜋(s, a) = E[Rt+1 + 𝛾q𝜋(St+1, At+1) | St = s, At = a]
Bellman Optimality Equation
- 가치함수의 역할은 정책을 정하고 정책을 따라갔을때 받는 보상들의 합인 가치함수로 더 좋은 정책을 찾는것이다.
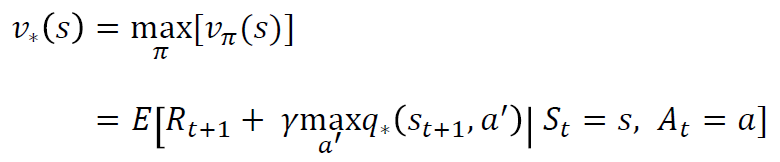
Dynamic Programming
큰 문제를 한번에 해결하기 힘들때 작은 여러개의 문제로 나눠 푸는 방법 ex)피보나치 수열
모든 상태에 대해 가치함수를 구하고 iteration을 돌며 각 상태에 대한 가치함수를 업데이트 한다.
5*5인 그리드 월드에서의 가치함수가 구해지는 과정이다.
itration 가치함수(v𝜋) 1 v0(s1),…, v0(s25) 2 v1(s1),…, v1(s25) … … k v𝜋(s1),…, v𝜋(s25)
정책 이터레이션: 정책 평가와 정책 발전
정책 이터레이션
다이나믹 프로그래밍으로 벨만방정식을 풀어서 가치함수를
구하는 과정이다.처음에는 무작위로 행동을 하고 iteration을 돌며 가치함수 최적화를 한다.
정책 평가
- 어떤 정책이 있을때 그 정책을 정책 평가 를 통해 얼마나
좋은지 판단하고 그 결과를 기준으로 더 좋은 정책 으로 발전 시킨다.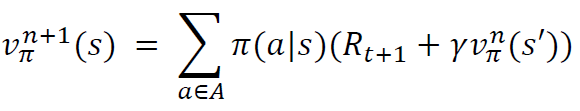
정책 발전
- 정책 평가를 바탕으로 정책을 발전시킨다.
- 탐욕 정책 발전(Greedy Policy Improvement)를 사용
- Q-Function을 사용하여 행동에 대한 가치함수를 알 수 있다.
- argmax는 가장 큰 큐함수를 가지는 행동을 반환하는 함수이다.
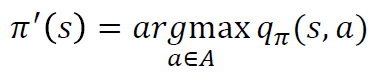
- 어떤 정책이 있을때 그 정책을 정책 평가 를 통해 얼마나
가치 이터레이션
- 가치 이터레이션은 가치함수가 최적이라는 전제하에 각 상태에 대한 가치함수를 업데이트 하는 방법이다.
(벨만최적방정식 사용한다) - 벨만 최적방정식에서는 현재 상태에서 가능한 최고의
가치함수 값을 고려하면 된다. - 벨만 최적 방정식과는 다르게 정책값을 이용해 기댓값을 계산하던 부분이 없어지고 max가 있다.

Q-Learning
Monte-carlo Approximation
몬테카를로 근사의 예시로 원의 넓이 구하기가 있다.
원의 넓이는 S = 𝜋r2 이다.
원의 넓이를 구하는 공식을 모를때 몬테카를로 근사를 사용할 수 있다.
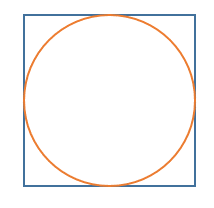
몬테카를로 근사로 원의 넓이 구하기
1 원이 그려진 종이위에 점을 무작위로 뿌린다.
2 뿌린 점들중 원에 들어간 점의 비율을 구하면 이미 알고있는 사각형의 넓이를 통해 원의 넓이를 추정할 수 있다.
3 뿌린 점의 비율로 (원의 넓이)/(사각형의 넓이) 를 근사하는 것이다.
파이썬으로 PI값 예측하기몬테카를로 예측에서 에이전트는 아래 식을 통해 에피소드 동안 경험한 모든 상태에 대해 가치함수를 업데이트 한다.
V(s) <- V(s) + α(G(s) - V(s))샘플수가 많을수록 정확한 가치함수 최적화가 가능하다.
Temporal Difference Prediction
시간차 예측은 타임스텝마다 가치함수를 업데이트 하는 방법이다.
몬테카를로 예측은 실시간으로 가치함수의 업데이트가 불가능하다.
다음 스텝의 보상과 가치함수를 샘플링하여 현재 상태의 가치함수를 업데이트한다.
V(St) <- V(St) + α(R + 𝛾V(St+1 - V(St)R + 𝛾V(St+1)를 시간차 에러(Temporal difference error)라고 한다.
따라서 시간차 예측은 어떤 상태에서 행동을 하면 보상을 받고
다음 상태를 알게되고 다음 상태의 가치함수와 알게된 보상을 더해
그 값을 업데이트의 목표로 삼는것을 반복한다.
SARSA
- SARSA = Policy Iteration(정책 이터레이션) + Value Iteration(가치 이터레이션)
- SARSA는 가치 이터레이션을 통해 문제를 해결한다.
- SARSA = 시간차 예측 + 탐욕정책(ε-greedy)
- SARSA에서 업데이트 하는것은 큐함수이다.
- 큐함수를 업데이트하기 위한 샘플로 [St, At, Rt+1, St+1, At+1]을 사용한다.
- ε만큼의 확률로 탐욕적이지 않은 행동을 선택하게 한다.
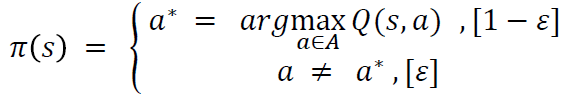
Q-Learning
- 큐러닝은 에이전트가 다음상태를 알게되면 그 상태에서 가장 큰 큐함수를 현재 큐함수의 업데이트에 사용한다.
- 온폴리시(On-Policy)학습의 경우 에이전트가 탐험할 때 문제점이 발생한다.
- 오프폴리시(Off-Policy) = Q-Learning으로 해결이 가능하다.
- 현재 상태의 큐함수를 업데이트하기 위해 필요한 샘플은 [s, a, r, s]이다.
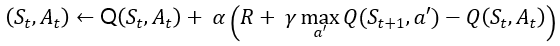
정리
TAVE 6기가 8월부터 시작되었다. 머신러닝을 공부하려고 들어왔지만, 강화학습이 너무 재미있어보여서 강화학습스터디에 참여하게 되었다. 첫 스터디는 조장님이 쭉 설명을 해주셨다. 수식도 많고 헷갈리는 부분이 많았지만 반복해서 보다보니 이해가 잘 되었다.
같은 팀원들이 관심도 많고 잘하는 사람들이 많아 더 열심히 해야될것 같다.
우리 스터디 블로그이다.: TAVE 6기 강화학습 스터디 블로그