Leacture: Deep Learning for everyone
Outline
- CNN
- RNN
- CrossEntropyLoss
CNN
- CNN(Convolutional Neural Network)은 합성곱 신경망으로 필터링 기법을 인공신경망에 적용함으로써 이미지를 더욱 효과적으로 처리하기 위해 처음 소개되었다.
- 자율주행 자동차, 얼굴인식같은 분야에 많이 이용된다.
Convolution
이미지 위에서 stride값 만큼 filter를 이동시키면서 겹쳐지는 부분의 각 원소의 값을 곱해서 모두 더한 값을 출력으로 하는 연산이다.
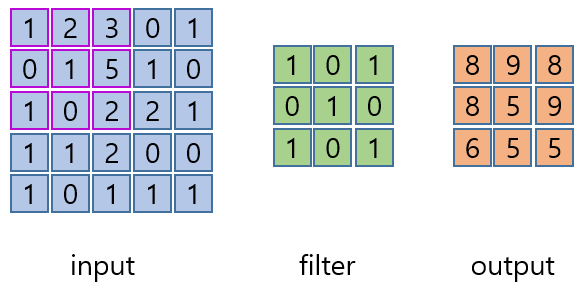
첫 번째 convolution 연산은 보라색 테두리와 필터의 연산이다.
같은 자리의 값고 곱한 후 그 값들의 합이 output의 1x1자리 값이 된다.
연산은 다음과 같다.
(1x1) + (2x0) + (3x1) +
(0x0) + (1x1) + (5x0) +
(1x1) + (0x0) + (2x1) = 8
stride
- filter를 한번에 얼마나 이동할 것인가?
padding
- zero-padding(0이 들어간 패드가 이미지 각 면에 둘러진다.)
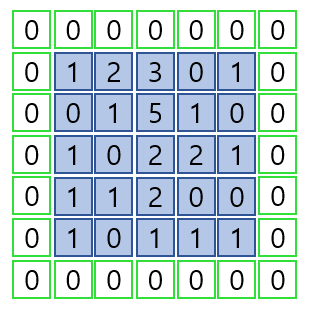
입력의 형태
- input type: torch.Tensor
- input shape: (N x C x H x W)
(batch_size, channel, height, width)
Convolution code
- convolution연산에서 output의 크기를 구하는 식이다.
outputsize = (input size - filter size + (2 * padding)) / stride + 1 - 227x227인 tensor를 11x11인 필터에 stride=4, padding 0으로 convolution연산을 하였다.
1 | import torch |
Pooling
- 이미지의 크기를 줄이기 위한 연산이다.
- 일정 크기의 블록을 통합하여 하나의 대푯갑으로 대체하는 연산이다.
- 입력데이터의 차원 감소하여 신경망의 계산효율성이 좋아지고 메모리 요구량의 감소가 일어난다.
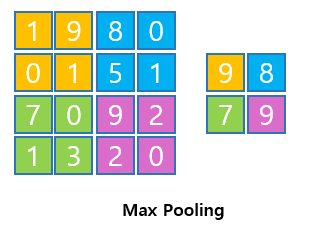
Max Pooling
1 | torch.nn.MaxPool2d(kernel_size, stride=None, padding=0 ...) |
- max pooling = 2일때 2x2사이즈 안에서 가장 큰값을 출력한다.
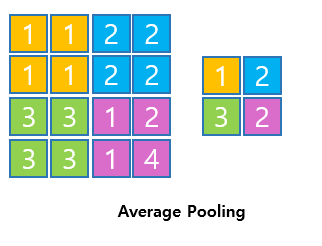
Average Pooling
- average pooling = 2일때 2x2사이즈 안에서 평균값을 출력한다.
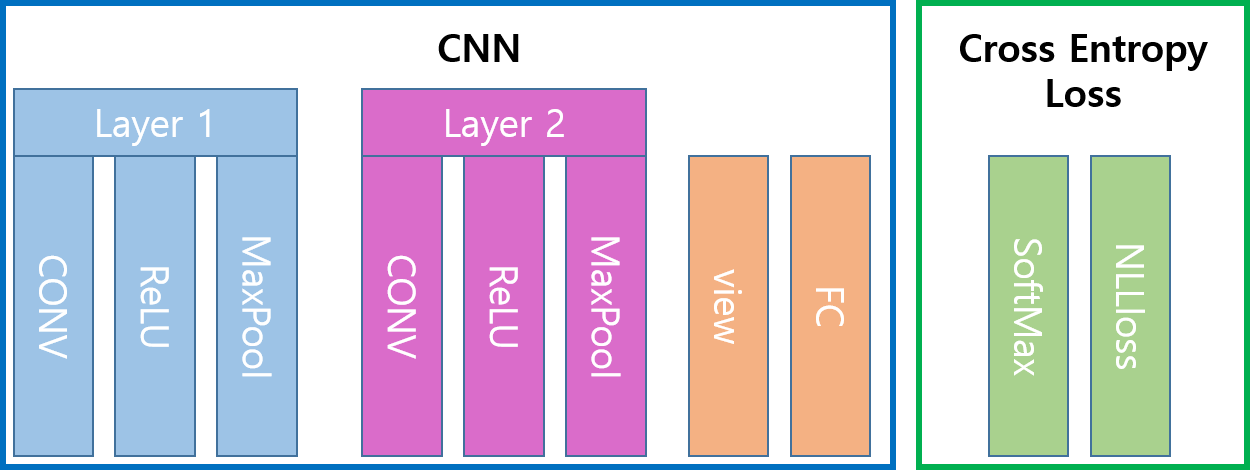
Mnist CNN
딥러닝을 학습시키는 단계
- 라이브러리 가져오기
- GPU 사용설정
- 데이터셋을 가져오고 로더 만들기
- Parameter 결정
- 학습 모델 만들기
- Loss function & Optimizer
- Training
- Test model Performance
MNIST를 이용하여 만들 CNN 구조
RNN
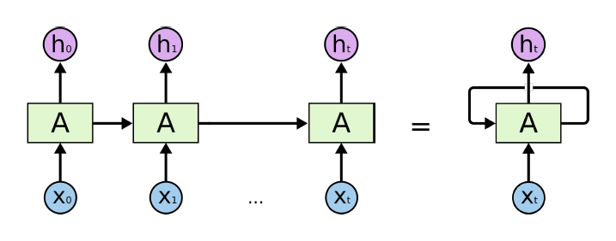
반복적이고 순차적인 데이터(Sequential data)학습에 특화된 인공신경망의 한 종류이다.
내부의 순환구조가 들어있으며 이를 이용하여 과거의 학습을 현재 학습에 반영한다.
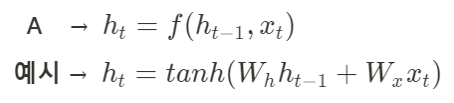
ht-1: 이전 상태값
xt: 현재 입력값
fw: w(Weight) parameter를 가지고 계산하는 함수
ht: 새로운 상태값
RNN의 다양한 구조
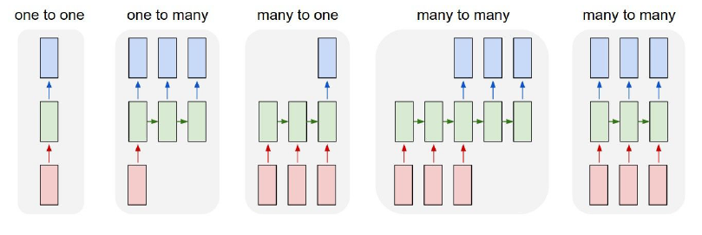
one to many
- 하나의 이미지가 들어가고 문장이 나온다.(자막)
many to one
- 문장이 입력, 하나의 값(감정에 대한 레이블)이 나온다.
many to many
- 문장이 들어가면 문장이 나온다.
- 번역 텍스트에 가능하다.
- 문장을 끝까지 보고 출력을한다.
many to many2
- 비디오, 이미지 입력, 출력값은 변화된 값이다.
- 이미지 캡셔닝
RNN Pytorch basics
1 | rnn = torch.nn.RNN(input_size, hidden_size) |
CrossEntropyLoss
- 정답 카테고리에서 최대한 올리는 것이다.
- criterion(모델의 output, 정답label)
1 | criterion = torch.nn.CrossEntropyLoss() |