Outline
- DQN
- Cartpole
- Cartpole Code
DQN(Deep Q Network)
DQN이란?
- DQN 알고리즘은 2013년 딥마인드가 “Playing Atari with Deep Reinforcement Learning”이라는 논문에서 소개되었다.
- DQN은 Deep SARSA와는 다르게 Q learning의 Q Function을 업데이트 한다.
- Q Function 업데이트를 가능하게 하기 위해 경험 리플레이를 사용한다.
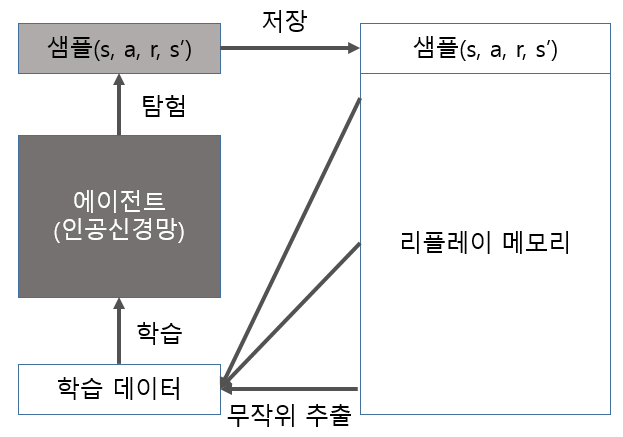
- 경험 리플레이는 에이전트가 환경에서 탐험하며 얻는 샘플(s, a, r, s’)을 메모리에 저장하는것이다.
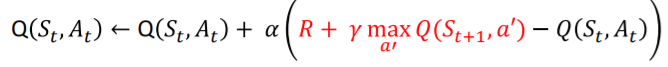
Q-learning의 Q함수 업데이트 식
DQN의 특징
- 타깃 신경망을 사용한다.
- 경험 리플레이를 사용 사용하는 에이전트는 매 타임스텝마다 리플레이 메모리에서 샘플을 배치로 추출해서 학습에 사용한다.
- 오류함수로 MSE사용한다.
경험 리플레이
- 환경에서 에이전트가 탐험하며 얻는 샘플(s,a,r,s’)를 메모리에 저장한다.
- 샘플을 저장하는 메모리는 리플레이 메모리이다.
- 에이전트가 학습할 때 샘플을 무작위로 뽑아 샘플에 대해 인공신경망을 업데이트 한다.
- 샘플간의 상관관계를 없앨 수 있다.
- 현재 에이전트가 경험하고 있는 상황이 아닌 다양한 과거의 상황으로부터 학습하기 때문에 오프폴리시가 적합하다.
- 그래서 q learning을 경험 리플레이 메모리와 사용하는것이다.
리플레이 메모리
- 크기가 정해져 있다.
- 메모리가 차면 처음들어온 것부터 삭제된다. (큐 방식)
- 에이전트가 학습해서 높은 점수를 받으면 더 좋은 샘플이 리플레이 메모리에 저장된다.
- 메모리에서 추출한 여러개의 샘플을 통해 인공신경망을 업데이트 하므로 학습이 안정적이다.
- 여러개의 gradient를 구하면 하나의 데이터에서 gradient를 구하는것보다 값 자체의 변화가 줄어 인공신경망 업데이트가 안정적이다.
[DQN Algorithm 구조]
Cartpole
Markov Decision Process (MDP)
상태(state) : 카트의 위치, 속도, 폴의 각도, 각속도
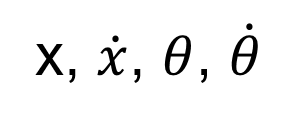
행동(action) : 왼쪽(0), 오른쪽(1)
보상(reward) : 카트폴이 쓰러지지 않고 버티는 시간
- 예를들어, 10초를 버티면 보상은 +10
- 여기선 단위가 초가 아니라 타임스텝
- 최대 500타임스텝까지 버틸 수 있음. 보상은 +500
- 중간에 카트폴이 쓰러지면 -100
- 감가율 : Q함수에 대한 discount
Cartpole Code
Environments
1 | # CartPole-v1 환경, v1은 최대 타임스텝 500, v0는 최대 타임스텝 200 |
- Cartpole을 실행할 환경을 생성한다.
- CartPole-v0 과 v1의 차이는 최대 타임스텝의 수 (각각 200, 500) - state_size = 4 (카트의 위치, 속도, 폴의 각도, 각속도)
- action_size = 2 (왼쪽으로 움직이기, 오른쪽으로 움직이기)
DQNAgent Class
1 | class DQNAgent: |
- DQNAgent class를 구성하고 있는 메서드들이다.
def __init__
1 | def __init__(self, state_size, action_size): |
I. Epsilon Greedy Algorithm
- epsilon decay : 1.0 에서 0.999씩 곱해지며 decay 된다.
- epsilon이 1이면 무조건 무작위로 행동을 선택한다.
- epsilon min : decay되는 최솟값이다.
II. Replay Memory
- Batch_size : 리플레이 메모리에서 무작위로 추출할 샘플의 사이즈다.
- Train_start : 리플레이 메모리에 1000개가 쌓이면 학습을 시작한다.
- Memory : 리플레이 메모리에 2000개가 쌓이면 일반적인 큐의 규칙에 의해 처음 들어온 데이터부터 삭제가 된다.
III. Target Network
- Model, target_model : 모델과 타깃모델 생성
- Q함수의 업데이트는 다음상태 예측값을 통해 현재 상태를 예측하는 부트스트랩 방식이다.
- 부트스트랩의 문제점은 업데이트 목표가 계속 바뀐다.
- 이를 방지하기 위해 정답을 만들어 내는 신경망을 한 에피소드동안 유지한다.
- 타겟 신경망을 따로 만들어서 정답에 해당하는 값을 구한다.
- 구한 정답을 통해 다른 인공신경망을 계속 학습시키며 타겟 신경망은 한 에피소드 마다 학습된 인공신경망으로 업데이트 한다.
build_model
1 | def build_model(self): |
update_target_model
1 | def update_target_model(self): |
get_action
1 | def get_action(self, state): |
- np.random.rand() : 0~1 사이 임의의 실수 1개
- self.epsilon : Epsilon Greedy Algorithm의 epsilon 값
- epsilon값이 더 크면 무작위 행동(왼쪽 or 오른쪽으로 움직이기)
- 그게 아니라면 계산한 두개의 Q값들 중 더 큰 값을 반환한다.
append_ sample
1 | def append_sample(self, state, action, reward, next_state, done): |
triain_model
1 | def train_model(self): |
- target은 현재 상태에 대한 모델의 큐함수이다.
- target_val은 다음 상태에 대한 타겟 모델의 큐함수이다.
Train
1 | scores, episodes = [], [] |