Loss Function
- 신경망에서는 하나의 지표를 기준으로 최적의 매개변수 값을 탐색한다. 신경망 학습에서 사용하는 지표는 손실 함수(loss function)이다.
SSE(sum of squares for error)
\begin{align}
E = {1/2} {\sum}_k{(y_k - t_k)^2}
\end{align}
- $y_k$는 신경망이 추정한 값, $t_k$는 정답 레이블, $k$는 데이터 차원의 수를 나타낸다.
1 | def SSE(y, t): |
1 | # t = 정답 레이블 |
- 정답은 ‘2’인 배열 안에서 SSE의 기준으로 첫 번째 추정 결과가 오차가 더 작기 때문에 정답에 가깝다고 판단 할 수 있다.
Entropy
엔트로피는 정보를 표현하는데 필요한 최소 평균 자원량이다.
자원량은 0 또는 1의 bits로 표현 한다.
인코딩시 확률이 낮은 것들은 길게 코딩하고 높은 것들은 짧게 코딩한다.
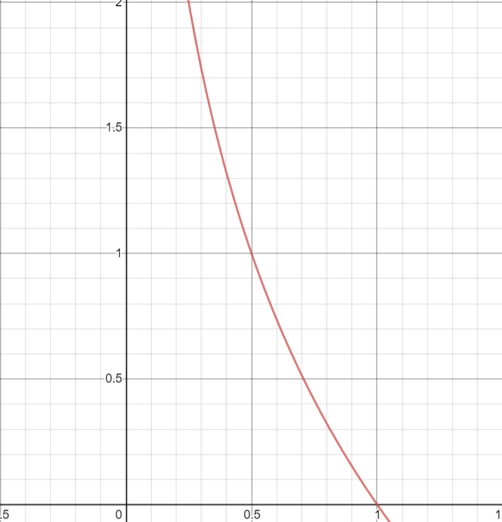
y축은 코딩되는 길이, x축은 확률이다.
아래 식은 확률에 따른 길이를 나타낸다.
\begin{align}
-\log_2{P_i}
\end{align}
- 자원량의 최소 기댓값이 최소 평균 길이다.
\begin{align}
E = {\sum}_i {p_i (-\log_2 P_i)}
\end{align}
CEE(cross entropy error)
Cross Entropy
- 교차 엔트로피는 추정한 기댓값이다
\begin{align}
E = {\sum}_i{p_i(-log_2 Q_i)}
\end{align}
1 | def CEE(y, t): |
1 | # t = 정답 레이블 |
- 오차 제곱합의 예시와 같이 정답은 ‘2’이다.
- delta는 np.log를 계산할 대 0이 입력되면 마이너스 무한대(-inf)가 되는 것을 방지하기 위해 아주 작은 수를 사용하였다.
- 오차값이 더 작은 첫 번째 추정이 정답이다.
KL Divergence(Kullback–Leibler divergence)
\begin{align}
KL(p||q) = -{\sum}_i {p_i \log({q_i / p_i})}
\end{align}
- KL divergence는 p와 q의 cross-entropy에서 p의 entropy를 뺀 값이다.
- cross entropy를 minimize 하는 것은 KL divergence를 minimize하는것과 같다. (p의 entropy는 고정된 값이기 때문)
학습 알고리즘 구현
- 2층 신경망을 구현해 본다.
미니 배치
훈련 데이터 중 일부를 무작위로 가져온다. 가져온 미니배치의 손실 함수 값을 줄이는것이 목표이다.
기울기 산출
미니배치의 손실 함수 값을 줄이기 위해 각 가중치 매개변수의 기울기를 구한다. 기울기는 손실 함수의 값을 가장 작게 하는 방향을 제시한다.
매개변수 갱신
가중치 매개변수를 기울기 방향으로 조금씩 갱신한다.
1~3을 반복한다.
two_layer_net.py
1 | import sys, os |
- __init__에서는 입력층과 은닉층의 뉴런 수, 출력층의 뉴런 수 예측을 인수로 받는다.
- predict함수는 예측을 수행한다. 파라미터 x는 이미지 데이터이다.
- accuracy함수는 정확도를 구한다.
- gradient함수는 가중치 매개변수의 기울기를 구한다. 오차 역전파(backward)를 사용하여 수치 미분을 사용하는것 보다 시간이 단축된다.
miniBatch_train_nNet.py
1 | import sys, os |
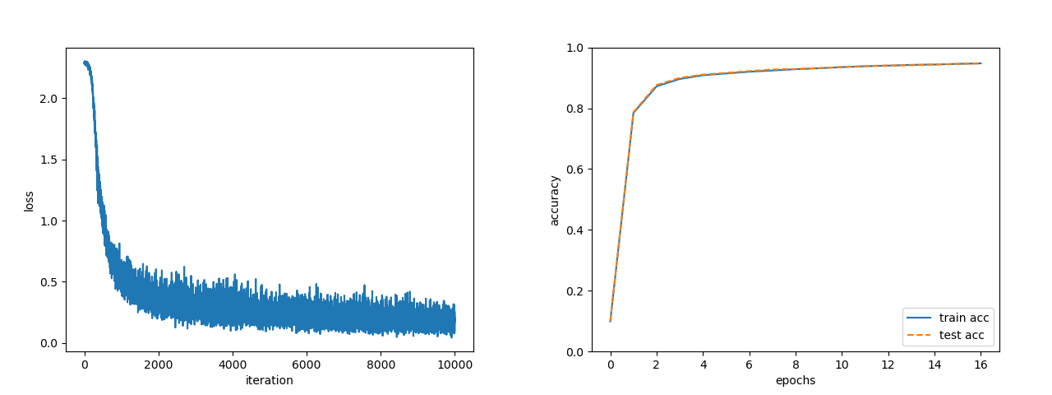
- 미니배치 크기를 100으로 하여 한번의 iteration을 수행할 때마다 임의로 100개의 데이터를 추린다.
- 100개의 미니배치를 대상으로 확률적 경사 하강법을 수행하여 매개변수를 갱신한다.
- 갱신할 때마다 훈련 데이터에 대한 손실 함수를 계산한다.
- 왼쪽 그래프는 각 iteration마다의 loss를 나타낸 것이고 오른쪽 그래프는 epch마다 훈련 데이터와 시험 데이터에 대한 정확도를 나타냈다.
- 훈련 데이터와 시험 데이터가 차이가 거의 없는것을 볼 수 있다.
References
코드: 밑바닥부터 시작하는 딥러닝
YouTube: 혁펜하임