Update Parameter
Optimization
- 신경망 학습의 목적은 손실 함수의 값을 가능한 낮추는 매개변수를 찾는 것이다.
SGD(확률적 경사 하강법)
\begin{align}
W \leftarrow W-\eta ({\partial L / \partial W})
\end{align}
1 | class SGD: |
- $\eta$는 learning rate이고, 실제로는 0.01이나 0.001과 같은 값을 정해서 사용한다.
- W는 가중치 매개변수이고, $\partial L / \partial W$는 가중치에 대한 손실함수(LOSS)의 기울기다.
- params와 grads는 딕셔너리 변수이다.
- params[‘W’], grads[‘W’]와 같이 각각의 가중치 매개변수와 기울기를 저장하고 있다.
Momentum
\begin{align}
v \leftarrow \alpha v - \eta ({\partial L / \partial W})
\end{align}
\begin{align}
W \leftarrow W+v
\end{align}
1 | class Momentum: |
- 초기화에서 v는 값이 없다.
- momentum은 변수 v가 추가되는데 v는 이전 학습결과도 반영한다.
- $\alpha$를 0.9로 설정한다면, 이전 학습결과를 0.9를 반영하고 현재 batch는 0.1을 반영하여 가중치를 업데이트 한다.
AdaGrad
\begin{align}
h \leftarrow h+{\partial L / \partial W} \odot {\partial L / \partial W}
\end{align}
\begin{align}
W \leftarrow W-\eta ({1 / {\sqrt {h}}})*({\partial L / \partial W})
\end{align}
1 | class AdaGrad: |
- h는 기존 기울기 값을 제곱해서 더해준다.
- 매개변수를 갱신할 때 $1 / \sqrt h$을 곱해 학습률을 조정한다.
- 학습률 감소가 매개변수의 원소마다 다르게 적용된다.
- 학습을 진행할 수록 갱신 강도가 약해지며, 무한히 학습하면 갱신량이 0이되어 갱신이 이루어지지 않는다.
- 이러한 갱신 문제는 RMSProp에서 해결한다.
- 코드에서는 1e-7을 더해주는데 0으로 나누는 일이 없도록 해준다.
RMSProp
\begin{align}
E[{\partial {_w}}^{2} D]_k = \gamma E[{\partial {_w}}^{2} D]_{k-1} +(1-\gamma)({\partial {_w}}^{2} D)_k
\end{align}
\begin{align}
w_{k+1} = w_k - ({\eta / \sqrt{E[{\partial {_w}}^{2} D]_{k+\epsilon}}}) * \partial_wD
\end{align}
1 | class RMSprop: |
- 이 코드에서는 decay rate를 0.9로 설정했다.
- Adagrad의 learning rate가 0으로 수렴하는 것을 개선하기 위해 기울기를 단순 누적하지 않고 지수 가중 이동 평균을 사용하여 최신 기울기가 더 크게 반영되도록 했다.
Adam
\begin{align}
{m_t} = {\beta_1} {m}_{t-1}+(1-{\beta_1})g_t
\end{align}
\begin{align}
v_t = {\beta_2}v_{t-1}+(1-\beta_2){g{_t}}^2
\end{align}
\begin{align}
\hat{m}_t = {m_t / 1-{\beta{_1}}^t}
\end{align}
\begin{align}
\hat{v} = {v_t / 1-{\beta{_2}}^t}
\end{align}
\begin{align}
\theta_{t+1} = \theta_t-({\eta / \sqrt{\hat{v_t}+\epsilon}}) \hat{m}_t
\end{align}
1 | class Adam: |
- Adam optimizer는 RMSProp과 Momentum을 합친 알고리즘이다.
- 1차 Momentum m과 2차 Momentum v를 이용하여 최적화를 진행한다.
Batch Normalization
Gradient vanishing, Exploding problem
신경망 학습시 gradient(변화량)이 매우 작아지거나 커지면 신경망을 제대로 학습시키지 못한다.
이런 문제를 해결하기 위한 트릭은 activation function 바꾸기(ReLU), 가중치 초기화하기, learning rate를 작게 하기가 있다.
학습 과정을 전체적으로 안정적이게 하여 학습 속도를 높여주는 Batch Normalization을 사용할 수 있다.
Batch Normalization
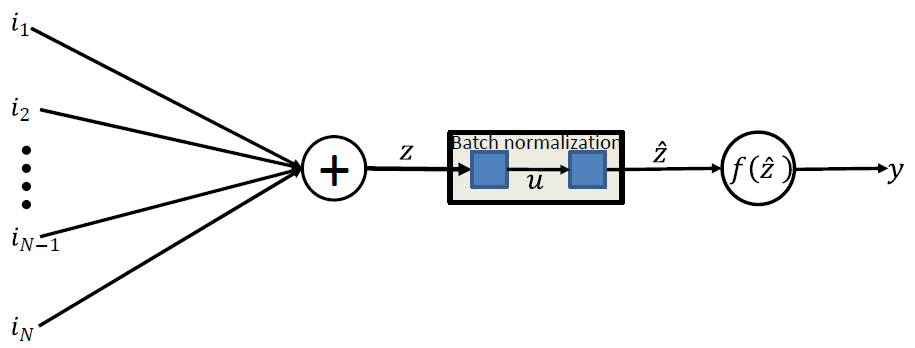
배치 정규화는 신경망 안에 포함되어 학습시 평균과 분산을 조정하는 역할을 한다.
레이어 마다 정규화 하는 레이어를 둬서 변형된 분포가 나오지 않게 한다.
미니 배치의 평균과 분산을 이용하여 정규화 한 후 scaling과 shift를 진행한다.($\gamma$ 와 $\beta$값을 이용)
\begin{align}
u_i = {z_i -\mu_B / \sqrt {\sigma{_B}^2 +\epsilon}}
\end{align}
\begin{align}
\hat {z}_i = \gamma u_i +\beta
\end{align}
- 미니 배치의 평균은 $\mu_B = {1 / B}{\sum_{i=1}}^B {z_i}$이고, 분산은 $\sigma{_B}^2 = 1/B {\sum{^B}}_{i=1} {(z_i - \mu_B)} $이다.
- $u_i$은 정규화 식이고, $\hat{z}_i$는 scaling과 shift이다.
For right learning
- 기계학습에서는 overfitting이 문제가 되는일이 많다.
- 신경망이 훈련 데이터에만 지나치게 적으오디어 그 외의 데이터에는 제대로 대응하지 못하는 상태를 overfitting이라고 한다.
Overfitting
- overfitting이 일어나는 경우
- 매개변수가 많고 표현력이 높은 모델
- 훈련 데이터가 적은 경우
1 | # coding: utf-8 |
60,000개인 MNIST 데이터셋의 훈련 데이터중 300개만 사용하고 7층 네트워크를 사용하였다.
각 층의 뉴런 갯수는 100개, activation function은 ReLU를 사용하였다.
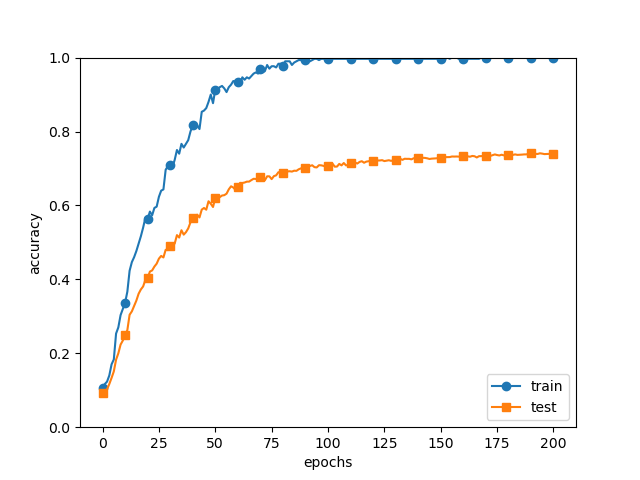
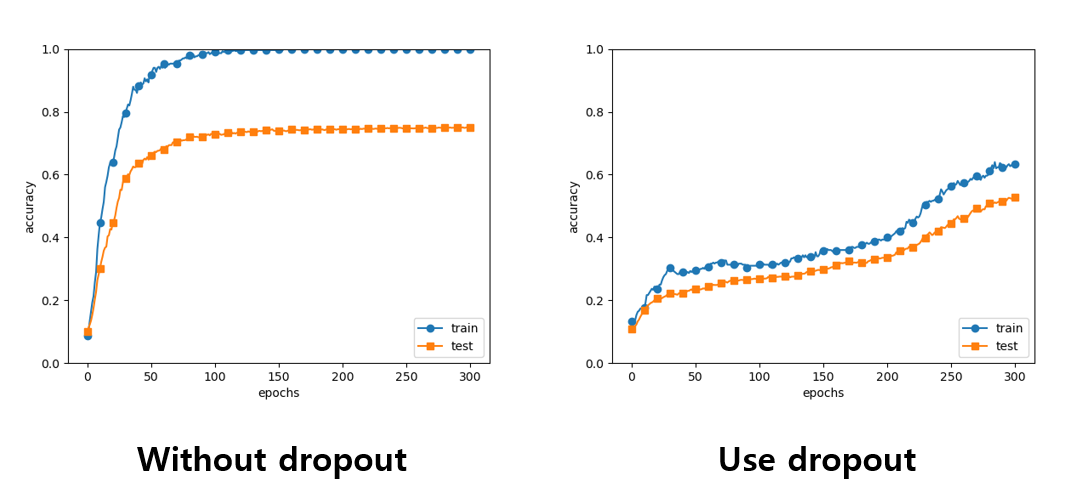
훈련 데이터를 사용한 것과 시험 데이터를 사용한 것의 정확도 차이가 크게 나는것을 볼 수 있다.
epoch마다 모든 훈련 데이터와 모든 시험 데이터에서 정확도를 산출한다.
훈련 데이터는 100 epoch 부분부터 100의 정확도를 보인다.
Weight decay
overfitting을 억제하기 위해 weight decay(가중치 감소)를 사용한다.
학습 과정 중에서 큰 가중치에 대해서는 그에 따른 큰 페널티를 부여하여 overfitting을 억제한다.
가중치 감소는 모든 가중치 각각의 손실 함수에 ${1 / 2}\lambda W$를 더해준다.
가중치의 기울기를 구하는 계산에서는 Backpropagation에 따른 결과에 정규화 항을 미분한 $\lambda W$를 더해준다.
가중치 감소를 추가해 준다.
1
2
3
4
5
6
7
8
9def loss(self, x, t):
y = self.predict(x)
weight_decay = 0
for idx in range(1, self.hidden_layer_num + 2):
W = self.params['W' + str(idx)]
weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2)
return self.last_layer.forward(y, t) + weight_decay1
2
3
4
5
6
7
8
9
10
11
12def gradient(self, x, t):
# forward
# backward
# 결과 저장
grads = {}
for idx in range(1, self.hidden_layer_num+2):
grads['W' + str(idx)] = self.layers['Affine' + str(idx)].dW + self.weight_decay_lambda * self.layers['Affine' + str(idx)].W
grads['b' + str(idx)] = self.layers['Affine' + str(idx)].db
return grads1
2
3weight_decay_lambda = 0.1
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10,
weight_decay_lambda=weight_decay_lambda)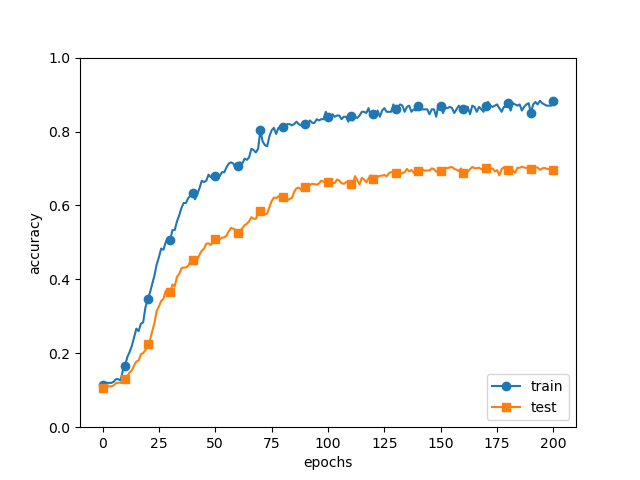
- overfitting이 억제된 것을 볼 수 있고, 훈련 데이터에 대한 정확도가 떨어진 것을 볼 수 있다.
Dropout
- 뉴런을 임의로 삭제하면서 학습하는 방법이다.
- 은닉층의 뉴런을 무작위로 골라 삭제한다.
- 훈련 시에는 삭제할 뉴런을 무작위로 선택하고, 시험 때는 모든 뉴런에 신호를 전달한다.
1 | class Dropout: |
self.mask는 x와 형상이 같은 배열을 무작위로 생성하고 그 값이 0.5(dropout_ratio)보다 큰 원소만 True로 설정한다.
Find the value of the appropriate hyperparameter
- 하이퍼파라미터는 각 층의 뉴런 수 , 배치 크기, 매개변수 갱신 시 학습률, 가중치 감소 등이다.
Validation data
- 하이퍼파라미터를 조정할 때 사용하는 데이터를 validation data(검증 데이터)라고 한다.
- MNIST 데이터셋에서 검증 데이터를 얻는 방법은 훈련 데이터 중 20% 정도를 검증 데이터로 분리하는 것이다.
1 | from common.util import shuffle_dataset |
Hyperparameter optimization
0단계
하이퍼파라미터 값의 범위를 설정한다
1단계
설정된 범위에서 하이퍼파라미터의 값을 무작위로 추출한다
2단계
1단계에서 샘플링한 하이퍼파라미터 값을 사용하여 학습하고, 검증 데이터로 정확도를 평가한다(epoch은 작게 설정한다.)
3단계
1단계와 2단계를 특정 횟수 반복하여 그 정확도의 결과를 보고 하이퍼파라미터의 범위를 좁힌다
1 | # 탐색한 하이퍼파라미터의 범위 지정 |
- 전체 코드는 hyperparameter_optimization.py에 있다.
이 글에 나왔던 common 폴더는 [common] 여기에 있다.