행 단위 데이터 추출하기
loc: 인덱스를 기준으로 행 데이터 추출iloc: 행 번호를 기준으로 행 데이터 추출
인덱스와 행 번호 개념
loc 속성으로 행 데이터 추출하기
1 | country continent year |
- 왼쪽의 번호가 인덱스이다
- 실제 데이터 프레임에서는 확인할 수 없는 값이다
1 | print(df.loc[0]) |
loc을 사용하면 행 데이터를 추출할 수 있다loc[-1]을 사용하면 뒤에서 첫 번째 데이터를 보여주지 않고 오류가 난다- 마지막 행 데이터를 추출하려면 데이터의 shape을 알아야 한다
1 | print(df.tail(n=1)) |
tail(n=1)을 사용하면 마지막 데이터를 알 수 있다loc[[0, 99, 999]]을 사용하면 원하는 인덱스 데이터를 알 수 있다
tail 과 loc 속성이 반환하는 자료형은 다르다
1 | sub_loc = df.loc[0] |
loc이 반환하는 자료형은Series이고tail이 반환하는 자료형은DataFrame이다
iloc 속성으로 행 데이터 추출하기
1 | print(df.iloc[1]) |
iloc속성으로 행 데이터를 추출할 수 있다loc속성은 데이터 프레임의 인덱스를 사용해서 추출했지만,iloc속성은 데이터 순서를 의미하는 행 번호를 사용하여 데이터를 추출한다loc속성과는 다르게df.iloc[-1]로 마지막 데이터를 추출할 수 있다- 여러 행을 추출하는 것은
loc과 동일하게iloc[[0, 99, 999]]로 사용하면 된다
슬라이싱과 range 메서드
1 | sub_sli = df.loc[:, ['year', 'pop']] |
- 모든 행에 대해
year과pop열을 추출하는 방법이다
1 | sub_range = df.iloc[:, list(range(5))] |
- 모든 행의 5번째 열까지 출력을 한다
df.iloc[:, list(range(3))]와df.iloc[:, :3]의 결과는 동일하다- 큰 규모의 데이터 분석에서는
loc속성이 유리하다
기초적인 통계 계산하기
그룹화한 데이터의 평균 구하기
1 | grouped_year_df = df.groupby('year') |
groupby()로 속성끼리 묶어서 데이터를 확인할 수 있다- 위 코드는 연도별로 그룹화한
lifeExp열을 얻을 수 있다 mean()메서드를 사용해 평균값을 알 수 있다
1 | unique = df.groupby('continent')['country'].nunique() |
nunique()를 사용하면 빈도수를 알 수 있다
그래프 그리기
1 | global_year_lifeExp = df.groupby('year')['lifeExp'].mean() |
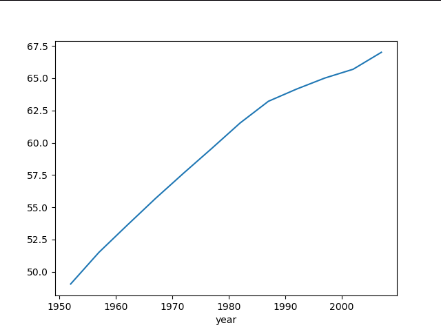
plot()메서드를 사용해서 그래프를 그릴 수 있다