Handson machin learning part1을 보고 정리한 내용입니다
머신러닝 프로젝트 진행 순서
- 큰 그림을 본다
- 데이터를 구한다
- 데이터로부터 통찰을 얻기 위해 탐색하고 시각화한다
- 머신러닝 알고리즘을 위해 데이터를 준비한다
- 모델을 선택하고 훈련한다
- 모델을 상세하게 조정한다
- 솔루션을 제시한다
- 시스템을 론칭하고 모니터링하고 유지보수한다
chapter 2에서는
StatLib저장소에 있는 캘리포니아 주택 가격 데이터셋을 사용한다
데이터 다운로드
1 | import os |
fetch_housing_data()를 호출하면 현재 작업공간에datasets/housing폴더를 생성하고housing.tgz파일을 내려받고 같은 폴더에 압축을 풀어housing.csv를 만든다
1 | import pandas as pd |
load_housing_data함수를 사용해 모든 데이터를 담은 판다스의 데이터프레임 객체를 반환한다
데이터 확인해보기
1 | from download_data import * |
- 이전 pandas 포스팅을 떠올리며 데이터를 확인해 보았다
head()를 사용해 데이터 상위 5개의 데이터를 조회한다info()를 사용해 데이터에 대한 간단한 설명과 전체 행 수, 각 특성의 데이터 타입과NULL이 아닌 값의 개수를 확인하는데에 사용한다
1 | ocean_proximity = housing['ocean_proximity'].value_counts() |
info()에서 확인한ocean_proximity의 데이터 타입은object(텍스트)이다- 텍스트 데이터 타입이므로 특성이
categorical한 것을 예상해 볼 수 있다 value_counts()를 사용해 각 카테고리가 얼마나 존재하는지 알 수 있다
1 | housing.describe() |
describe()를 사용해 숫자형 특성을 가진 데이터의 요약 정보를 보여준다
데이터 히스토그램 확인
1 | housing.hist(bins=50, figsize=(20, 15)) |
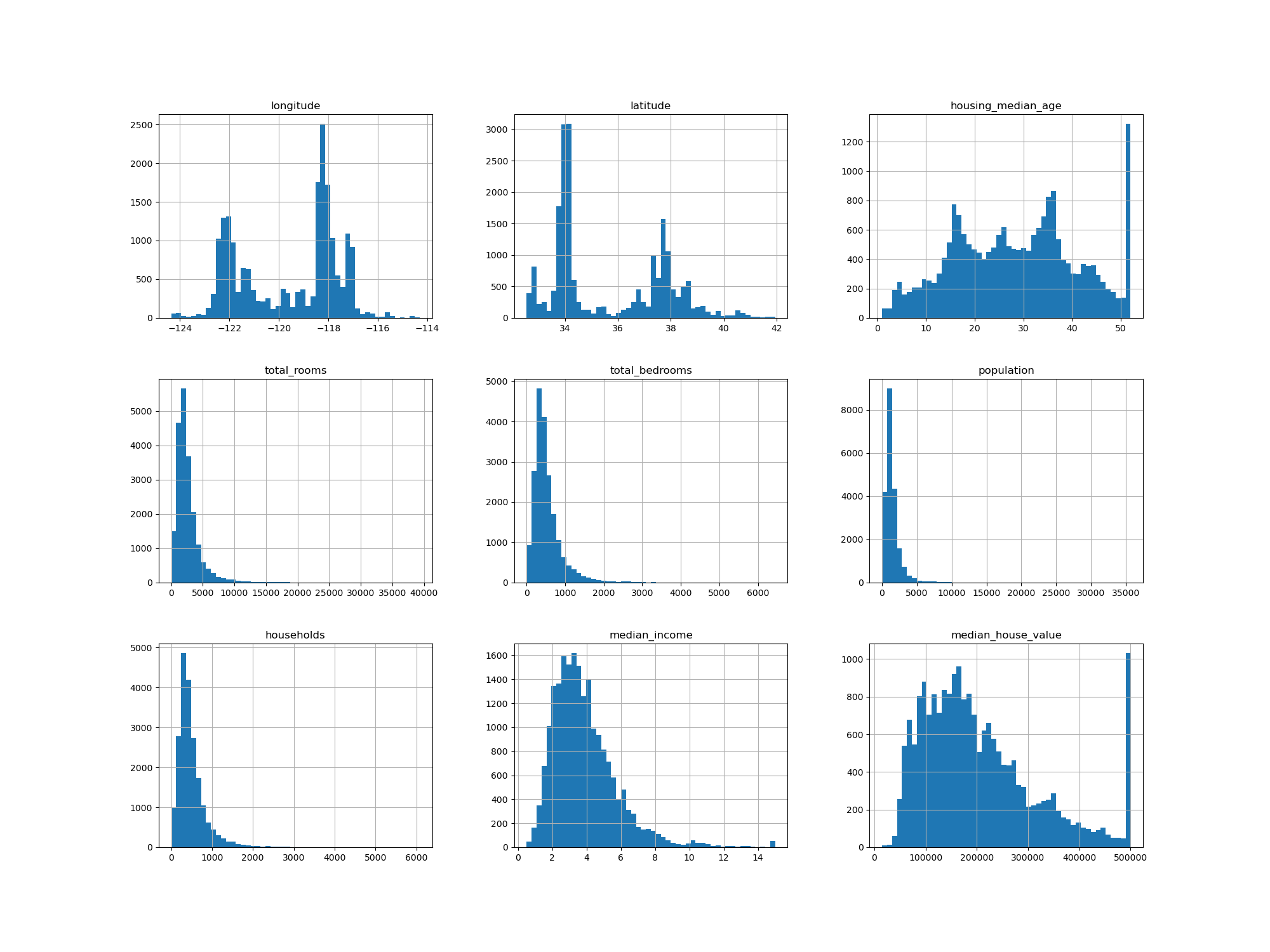
matplotlib을 import 해주고hist()를 이용해 데이터의 히스토그램을 그릴 수 있다
테스트 세트 만들기
데이터 스누핑 편향
- 테스트 세트를 알고 있다면 테스트 세트의 패턴을 인지하고 특정 머신러닝 모델을 사용하게 될 수 있다
- 테스트 세트로 일반화 오차를 추정하면 높은 성능이 나오며 서비스 론칭 시 기대한 성능이 나오지 않을 수 있다
계층적 샘플링
- 순수하게 무작위로 샘플링하는 방식은 샘플링 편향이 생길 수 있다
- 예를들어 설문조사를 하면 무작위로 사람을 뽑지 않고 각 그룹을 대표할 수 있게 비율을 맞춰 뽑는다
- 계층적 샘플링은 테스트 세트가 전체 인구(현재 예제)를 대표하도록 각 계층에서 올바른 수의 샘플을 추출한다
소득 카테고리 기반 계층 샘플링
1 | def train_test(): |
상관관계 조사
1 | corr_matrix = housing.corr() |
- 중간 주택 가격과 다른 특성 사이의 상관관계 크기를 알 수 있다
- 상관관계의 범위는 -1에서 1까지이며 1에 가까울수록 강한 양의 상관관계를 가진다
- 계수가 0에 가까우면 선형적인 상관관계가 없다는 뜻이다
머신러닝 알고리즘을 위한 데이터 준비
데이터 정제
- 머신러닝 알고리즘은 누락된 특성을 다루지 못한다
total_bedrooms특성에 값이 누락되어 있는데 이를 해결할 방법은 세 가지이다- 해당 구역을 제거
- 전체 특성을 삭제
- 값으로 채우기 (중간값, 0, 평균)
1 | housing.dropna(subset=['total_bedrooms']) # 옵션 1 |
- 중간값은 시스템 평가 시 누락된 값과 시스템 실제 운영 시 누락값을 채우기 위한것이다
sklearn SimpleImputer
1 | # 중간값으로 대체 |
strategy속성을 “median”으로 설정해 중간값으로 대체해준다ocean_proximity는 수치형 특성이 아니기에 제외하고 저장해준다- imputer는 각 특성의 중간값을 계산해 결과를 객체의
statistics_속성에 저장한다 X는 평범한 넘파이 배열이므로 판다스 데이터프레임으로 되돌릴 수 있다
텍스트와 범주형 특성 다루기
1 | ordinal_encoder = OrdinalEncoder() |
OrdinalEncoder은 카테고리를 텍스트에서 숫자로 변환해서 표현해준다OneHotEncoder는 1이 하나이고 나머지가 0인 배열로 반환해주고toarray()메서드를 호출하면 넘파이 배열로 나타낼 수 있다ordinal_encoder와cat_encoder의categories_인스턴스를 사용하면 어떤 카테고리가 있는지 알 수 있다
나만의 변환기
1 | rooms_ix, bedrooms_id, population_ix, households_ix = 3, 4, 5, 6 |
- 사이킷런이 다양한 변환기를 제공하지만 어떤 특성을 조합하는 등의 작업이 필요해 직접 변환기를 만들어야 할 필요가 생긴다
class를 구현하고fit과transform()을 만들어 구현한다- 조합 특성을 추가하는 간단한 변환기이다
- 데이터 준비 단계에서 자동화할수록 더 많은 조합을 시도할 수 있으며 최상의 조합을 찾을 가능성이 높다 (시간도 절약된다!!)
특성 스케일링
- 모든 특성의 범위를 같도록 만들어주는 방법으로
min-max스케일링과 표준화가 사용된다
변환 파이프라인
1 | num_pipeline = Pipeline([ |
sklearn에는 연속된 변환을 순서대로 처리할 수 있도록 도와주는Pipeline클래스가 있다Pipeline은 연속된 단계를 나타내는 이름/추정기 쌍의 목록을 입력으로 받는다- 마지막 단계에는 변환기와 추정기를 모두 사용할 수 있어야 하고 이외에는 모두 변환기여야 한다 (
fit_transform()메서드를 가지고 있어야 한다) - 파이프라인의
fit()메서드를 호출하면 모든 변환기의fit_transform()메서드를 순서대로 호출하며 한 단계의 출력을 다음 단계의 입력으로 전달한다, 마지막 단계에서는fit()메서드만 호출한다 - 파이프라인 객체는 마지막 추정기와 동일한 메서드를 제공한다
1 | from sklearn.compose import ColumnTransformer |
ColumnTransformer를 이용해 하나의 변환기로 각 열마다 적절하게 변환을 적용해 모든 열을 처리할 수 있다
모델 선택과 훈련
훈련 세트에서 훈련하고 평가하기
Linear Regression
1 | from sklearn.linear_model import LinearRegression |
k-fold cross-validation
1 | from sklearn.model_selection import cross_val_score |
Random Forest
1 | from sklearn.ensemble import RandomForestRegressor |
housing_prepared과housing_labels을 각 모델의 입력으로 사용해 간단하게 모델을 훈련할 수 있다
모델 저장하기
1 | import joblib |
모델 세부 튜닝
- 가능성 있는 모델을 추렸다고 가정하고 모델을 세부 튜닝을 한다
그리드 탐색
1 | from sklearn.model_selection import GridSearchCV |
GridSearchCV을 사용해 랜덤 포레스트 모델의 가능한 모든 하이퍼 파라미터 조합에 대해 교차 검증을 사용해 평가하게 된다
1 | grid_search.best_params_ |
best_params_로 최적의 조합을 얻을 수 있다best_estimator_로 최적의 추정기를 확인할 수 있다GridSearchCV의refit=True로 초기화되었다면 교차 검증으로 최적의 추정기를 찾고 전체 훈련 세트로 다시 훈련시킨다. 이 방법은 많은 데이터를 사용하기에 성능 향상에 도움이 된다
1 | cvres = grid_search.cv_results_ |
- 그리드 서치에서 테스트한 하이퍼파라미 조합들의 점수를 확인할 수 있다
랜덤 탐색
- 하이퍼파라미터 탐색 공간이 커지면
RandomizedSearchCV를 사용하는것이 좋다 - 랜덤 탐색을 1000회 반복하도록 실행하면 하이퍼파라미터마다 각각 다른 1000개의 값을 탐색한다
- 반복횟수를 조절하는것으로 하이퍼파라미터 탐색에 투입할 컴퓨팅 자원을 제어할 수 있다
앙상블 방법
- 최상의 모델을 연결해보는것이다
- 모델의 그룹이 최상의 단일 모델보다 더 좋은 성능을 낼 수 있다
- 결정 트리의 앙상블인 랜덤 포레스트가 결정 트리 하나보다 좋은 성능을 보이는것을 예로 들 수 있다
최상의 모델과 오차 분석
1 | feature_importances = grid_search.best_estimator_.feature_importances_ |
feature_importances_는 정확한 예측을 만들기 위한 각 특성의 상대적 중요도를 보여준다- 이 정보를 통해 덜 중요한 데이터의 특성들을 제외할 수 있다
테스트 세트로 시스템 평가하기
1 | final_model = grid_search.best_estimator_ |
- 테스트 세트에서 훈련을 하면 안되기 때문에
fit_transform()이 아닌transform()을 호출해야 한다
1 | from scipy import stats |
scipy.stats.t.interval()을 사용해 일반화 오차의 95% 신뢰 구간을 계산할 수 있다- 테스트 세트에서는 성능을 향상시키려고 하이퍼파라미터 튜닝을 시도하면 안된다